Go Get Yourself a Search Engine
Jul. 16, 2022 [Technology] [Privacy-Security] [Libre]The independent search engines which promised netizens that they would honor their word not to track, censor or advertise have continually been caught doing just that. DuckDuckGo has proven time and again that it should never be trusted. Qwant has pledged their allegiance to the cause of censorship. Startpage has sold out to an advertising firm. The list goes on and, if you’re reading this, I’m sure you’ve experienced your own share of backstabbings by trusted search engines.
One way that others have dealt with this is to migrate to metasearch engines which liaison your search queries to a plethora of different commercial engines. This helps to obfuscate search requests as well as mitigating some censorship. But it is still incomplete. The remainder of alternate search users continue to island hop from each new privacy friendly search engine to the next, as they fall like dominoes to the temptation of betraying their users.
The truth is that web search suffers from the same problem as DNS. No matter how you configure and use it, you are always in the precarious position of relying on and trusting a third party not to betray you. The root cause of these web search woes is that people do not have their own web indexes. And keeping a searchable web index is not as daunting as it may seem.
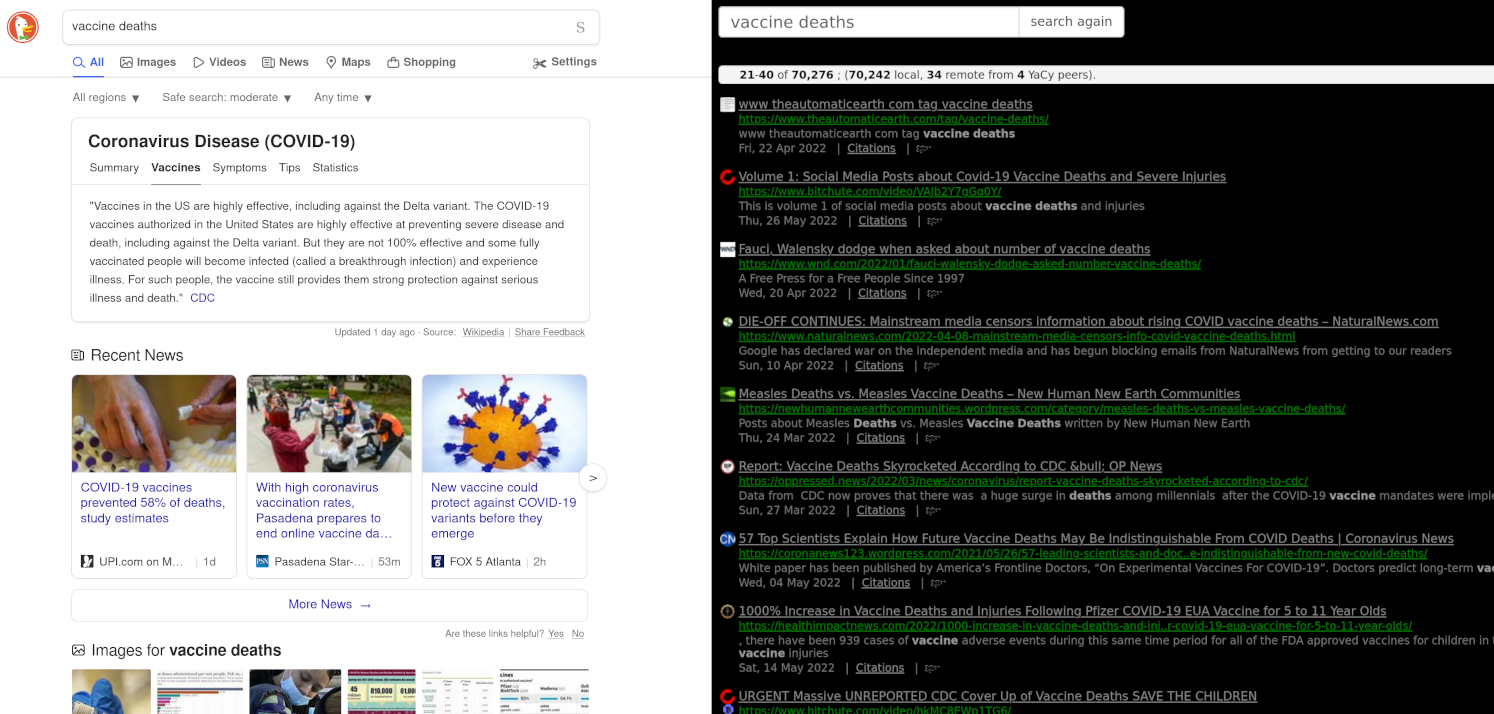
There are a few software out there that can be self-hosted such as Gigablast and YaCy which both crawl the web and provide web frontends for searching the resulting index. The great thing is that you can give them a generic starting domain list for impartiality and privacy (remember, your ISP can see all the addresses the crawler connects to) so it’s like hiding in a crowd. You get a search portal that works even if you later lose internet connectivity. It cannot be censored, nobody knows what queries you make and you are in total control.
I may eventually post a guide on setting up such a soluton. They typically need a few days to crawl before you have a viable index, but that’s a small price to pay for ultimate freedom from hidden hand search manipulation. And regardless of whether a DIY search engine is practical for everyone, it might be a good idea to also revisit the concept of webrings, considering the way things are headed right now.